Em OPSWAT, valorizamos a inovação, a criatividade e a melhoria contínua quando desenvolvemos soluções avançadas para proteger infra-estruturas e organizações críticas contra ciberameaças. Estes valores inspiraram-nos a criar o OPSWAT MetaDefender Threat Intelligence , que nos permite compreender e detetar melhor as ciberameaças em evolução para detetar e identificar ficheiros semelhantes.
À medida que as variantes de malware se tornam cada vez mais sofisticadas e evasivas, as soluções antivírus tradicionais baseadas em assinaturas são insuficientes. Para enfrentar este desafio, os especialistas em cibersegurança da OPSWAT desenvolveram uma solução elegante que utiliza tecnologia de análise estática de ponta e aprendizagem automática para identificar semelhanças partilhadas entre ficheiros. Esta abordagem fornece um meio eficiente de mitigar os riscos de cibersegurança e prevenir potenciais ataques.
A criação do MetaDefender Threat Intelligence deu-nos a oportunidade de resolver um problema difícil e urgente. Conseguimos desenvolver soluções eficazes de cibersegurança que fornecem às organizações a informação de que necessitam para antecipar e preparar-se para ameaças emergentes. Isto alinha-se com a nossa cultura de inovação e com o nosso compromisso de oferecer a melhor proteção possível aos nossos clientes.

Os dados
Para realizar pesquisas de semelhança, os ficheiros são submetidos a um rigoroso processo de análise que utiliza as tecnologias de análise estática e de emulação de ficheiros MetaDefender . Esta tecnologia avançada extrai as informações mais relevantes e úteis de um determinado ficheiro.
Os nossos analistas especializados em malware determinaram as funcionalidades mais eficazes para calcular as semelhanças entre dois ficheiros. Estas características são cuidadosamente seleccionadas com base na sua capacidade de fornecer resultados precisos e relevantes, e são continuamente actualizadas para se manterem a par das últimas tendências e técnicas de malware.
Algumas características são:
- Metadados binários (tamanho do ficheiro, entropia, arquitetura, caraterística do ficheiro e muitos outros)
- Importações
- Recursos
- Secções
- Sinais
- E mais
Nota: Ao procurar semelhanças entre ficheiros, é importante utilizar sinais gerados por Filescan e não confiar apenas no veredito final (Malicioso, Informativo, etc.) de um ficheiro. Esta abordagem ajuda a evitar quaisquer potenciais enviesamentos que possam surgir durante o processo de pesquisa de semelhanças.
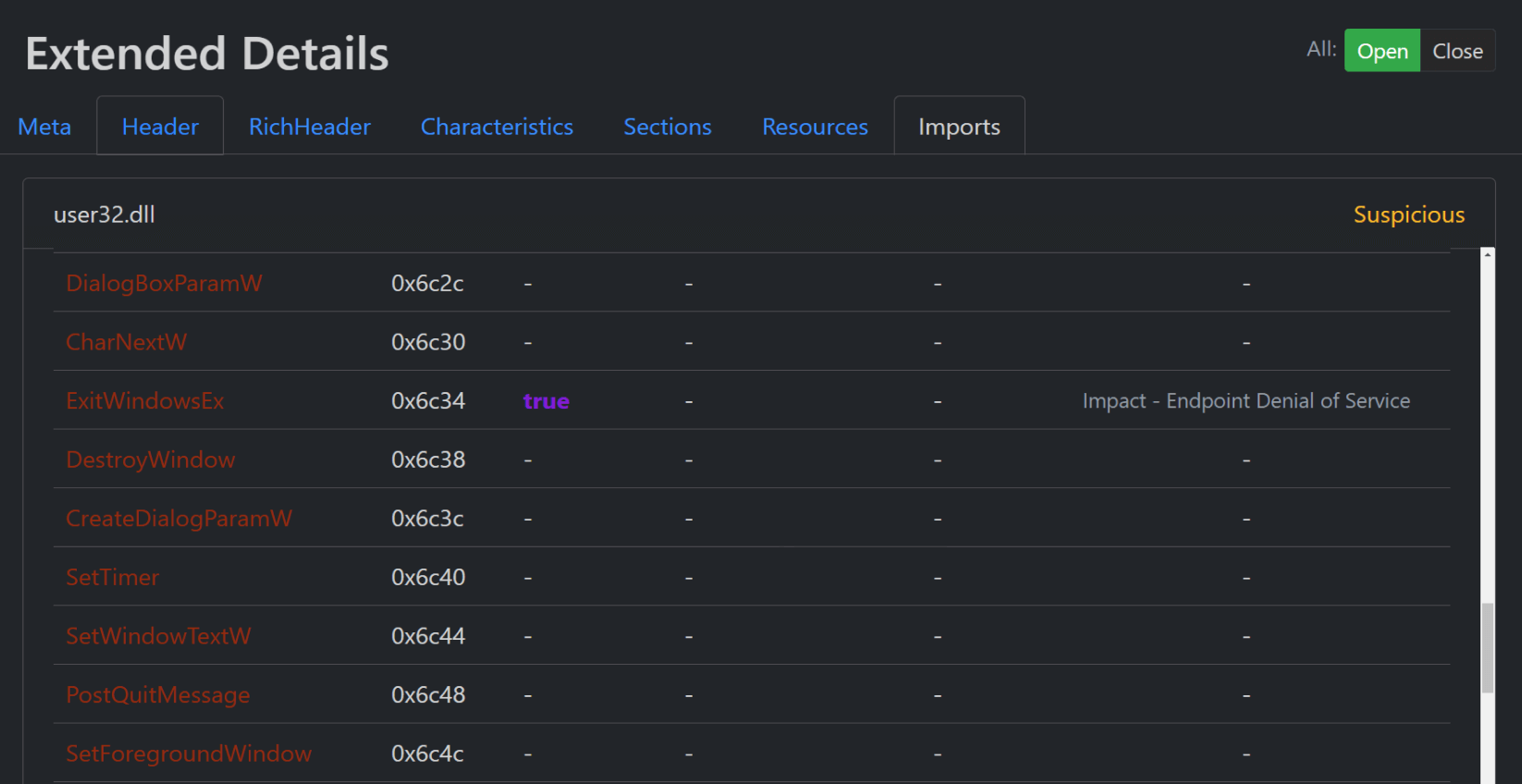

Processo
O processo de Pesquisa de Similaridade envolve a extração e transformação destas características de ficheiros Portable Executable (PE) em embeddings vectoriais. As incorporações vectoriais representam os dados como pontos num espaço n-dimensional, permitindo que pontos de dados semelhantes se agrupem, criando uma impressão digital do ficheiro. O número de dimensões é decidido por cada secção, reduzindo a dimensionalidade.
A solução utiliza então vários cálculos de distância modificados entre estes vectores para encontrar os ficheiros mais semelhantes, permitindo-nos responder à pergunta "qual a semelhança entre este ficheiro e outro?". A arquitetura e o algoritmo utilizam métodos de indexação que garantem um processamento rápido, mesmo quando se pesquisam milhões de ficheiros. A análise algorítmica destes campos permite à solução identificar e isolar com precisão ficheiros e ameaças semelhantes.
Para além da tecnologia avançada, a Pesquisa de Similaridade fornece uma interface personalizável que permite aos utilizadores filtrar os seus parâmetros de pesquisa. Esta funcionalidade oferece maior flexibilidade e assegura que os utilizadores recebem os resultados mais precisos e relevantes para as suas necessidades específicas.
Filtros:
- Etiquetas
- Veredicto
- Limiar de semelhança
O oleoduto
O processo de pipeline envolve a obtenção de um novo ficheiro PE de entrada, como um executável, e a sua sujeição a modelos de aprendizagem automática que geram incorporação de vectores com base em características pré-seleccionadas. Estes vectores são então incorporados num espaço vetorial, que pode ter qualquer número de dimensões.

Utilizamos várias métricas de distância para calcular a semelhança entre vectores e características, o que nos ajuda a determinar o ponto mais próximo de um determinado ficheiro PE de entrada.

Pontuação de similaridade
É importante notar que as pontuações de semelhança não são absolutas e podem ser algo subjectivas. Não existe uma fórmula ou norma universalmente aceite para determinar o grau de semelhança entre ficheiros, uma vez que este pode variar consoante o contexto e o caso de utilização específico. Por isso, é importante interpretar as pontuações de similaridade com cautela e considerar a metodologia utilizada para as calcular. A pesquisa de similaridade utiliza pesos para calcular uma pontuação de similaridade exacta.
Resultados MetaDefender
O resultado do Filescan fornece informações completas sobre o ficheiro utilizado para a pesquisa de semelhanças. No entanto, é importante analisar minuciosamente estas informações para compreender totalmente as características e propriedades do ficheiro. A IU apresenta várias propriedades de uma pesquisa de ficheiros e gera um relatório detalhado das suas características.
Para aceder à funcionalidade de pesquisa de semelhanças, navegue para o lado esquerdo da interface do utilizador. Por defeito, a funcionalidade de pesquisa de semelhanças é iniciada automaticamente com parâmetros predefinidos. Além disso, os utilizadores dispõem de várias opções de filtragem para os ajudar a personalizar a sua pesquisa e obter resultados óptimos com base nos seus requisitos específicos.
Filtros:
- Etiquetas: Estas são etiquetas dinâmicas atribuídas aos ficheiros com base nos seus atributos. Ao utilizar a funcionalidade de pesquisa por semelhança, as etiquetas podem ser utilizadas para etiquetar ficheiros com características específicas, tais como peexe ou shell32.dll. As etiquetas ajudam nas pesquisas direccionadas e eficientes, permitindo aos utilizadores encontrar rapidamente ficheiros que satisfaçam as suas necessidades específicas.
- Veredicto: O veredito de Filescan fornece o resultado de uma verificação realizada no ficheiro, indicando se o ficheiro é limpo, malicioso ou potencialmente prejudicial de alguma forma. Ao utilizar o veredito de Filescan como filtro, os utilizadores podem refinar os resultados da pesquisa para excluir ficheiros assinalados como maliciosos ou suspeitos.
- Limite de similaridade: Este é um parâmetro configurável que determina o nível mínimo de semelhança necessário para que os ficheiros sejam incluídos nos resultados da pesquisa. Ao ajustar este limite, os utilizadores podem personalizar os resultados da pesquisa para satisfazerem as suas necessidades específicas. Por exemplo, podem encontrar ficheiros que estão intimamente relacionados ou aqueles que têm uma ligação mais ténue. Este filtro é útil para os utilizadores que necessitam de equilibrar a precisão com uma pesquisa ampla e abrangente.
Separadores
Na funcionalidade de pesquisa por semelhança, são apresentadas aos utilizadores opções de filtragem predefinidas sob a forma de separadores. Estes separadores permitem aos utilizadores filtrar os resultados com base nos ficheiros mais semelhantes, nos ficheiros mais recentes e nos ficheiros que foram assinalados com um veredito malicioso. Estas opções de pré-filtragem foram concebidas para melhorar a eficiência e a precisão da experiência de pesquisa para os utilizadores.

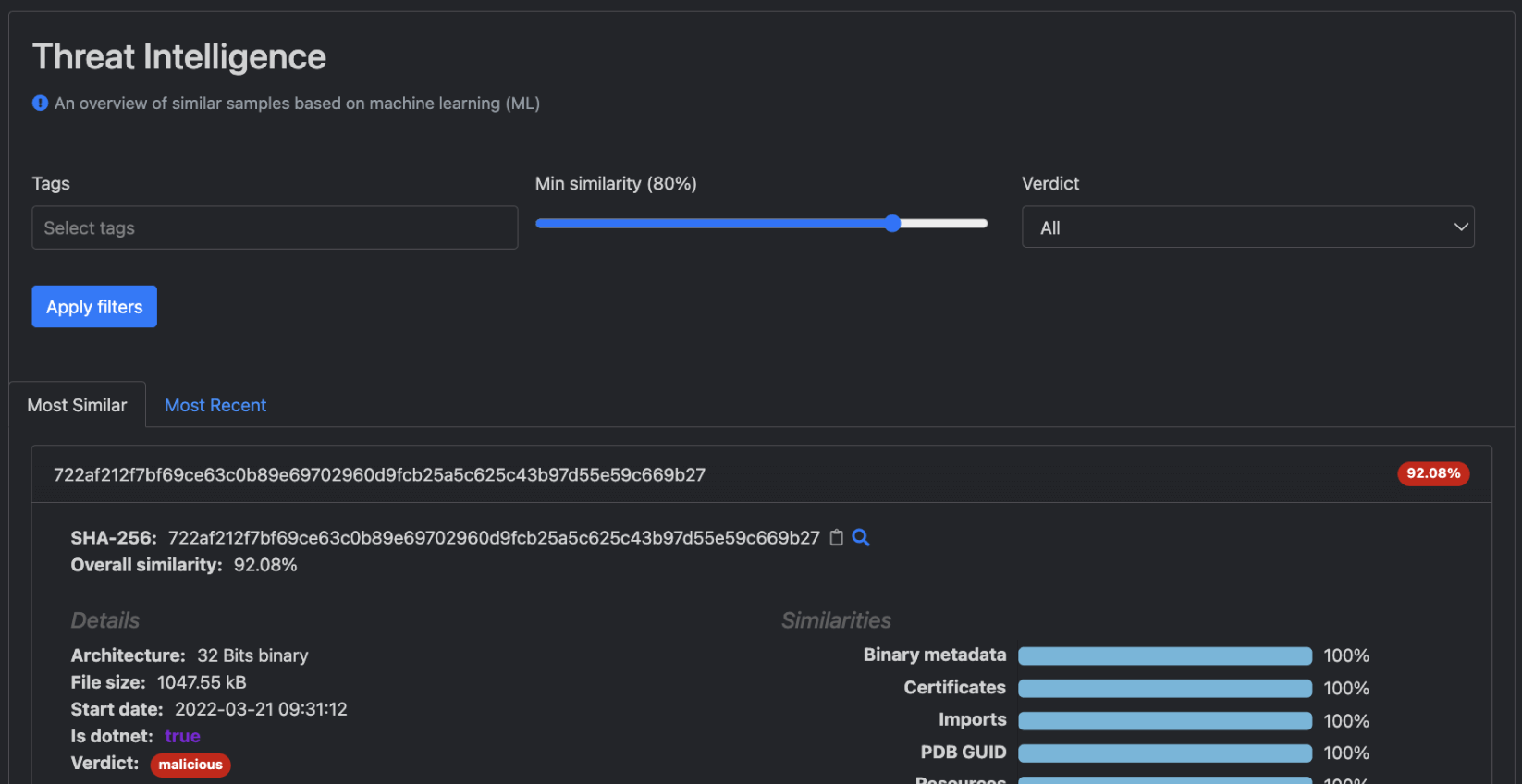
Threat Intelligence Subpágina
A subpágina Threat Intelligence oferece aos utilizadores uma variedade de funcionalidades, tais como a capacidade de visualizar os ficheiros mais estreitamente relacionados e utilizar a interface de utilizador filtrável. Ao selecionar um identificador SHA256 específico, os utilizadores podem obter informações detalhadas sobre a semelhança do ficheiro associado, juntamente com os seus detalhes de alto nível.
Principais casos de utilização
Como em qualquer aplicação de aprendizagem automática, é crucial validar os resultados de uma pesquisa por semelhança. No entanto, esta funcionalidade oferece uma vasta gama de possibilidades para os utilizadores explorarem e identificarem eficazmente ficheiros relevantes. A pesquisa de indexação fornece uma pesquisa de hash excecionalmente rápida para todos os tipos de ficheiros, constituindo a pedra angular do produto. As seguintes entidades podem beneficiar da funcionalidade de pesquisa por semelhança.
- Analistas cibernéticos threat intelligence , que podem tirar partido desta capacidade para investigar e detetar ameaças novas e em evolução, melhorando a postura de segurança da sua organização.
- Caçadores de ameaças, que podem procurar proactivamente indicadores de comprometimento (IOCs) e potenciais vulnerabilidades, prevenindo assim actividades maliciosas.
- Qualquer pessoa interessada em explorar as relações entre ficheiros e identificar semelhanças, incluindo investigadores, investigadores e analistas.
Obter acesso à Pesquisa de Similaridade
Descubra como pode integrar a pesquisa por semelhança nos seus processos lendo a nossa documentação em https://www.opswat.com/docs. Tenha em atenção que a funcionalidade de pesquisa por semelhança é um suplemento disponível exclusivamente para os nossos utilizadores do pacote pago Filescan ou Threat Intel. Se estiver interessado em explorar esta funcionalidade, inscreva-se numa conta hoje mesmo!

