A falsificação de ficheiros continua a ser uma das técnicas mais eficazes que os atacantes utilizam para contornar os controlos de segurança tradicionais. No ano passado, OPSWAT introduziu um motor de deteção de tipos de ficheiros melhorado por IA para colmatar as lacunas deixadas pelas ferramentas antigas. Este ano, com o Modelo de Deteção de Tipos de Ficheiros v3, avançámos essa capacidade, concentrando-nos nos tipos de ficheiros em que a precisão é mais importante e em que os sistemas tradicionais baseados na lógica ficam sempre aquém.
OPSWAT File Type Detection Model v3 foi concebido para responder a um desafio específico de classificação fiável de ficheiros ambíguos e não estruturados, especialmente formatos baseados em texto, como scripts, ficheiros de configuração e código fonte. Ao contrário dos classificadores generalizados, este modelo foi concebido especificamente para casos de utilização de cibersegurança, em que a classificação incorrecta de um script de shell ou a incapacidade de detetar um documento que contenha macros incorporadas, como um ficheiro Word com código VBA, pode introduzir um risco de segurança significativo.
Porque é que a verdadeira deteção do tipo de ficheiro é fundamental
A maioria dos sistemas de deteção baseia-se em três abordagens comuns:
- Extensão do ficheiro: Este método verifica o nome do ficheiro para determinar o seu tipo com base na extensão, como .doc ou .exe. É rápido e amplamente compatível com todas as plataformas. No entanto, é facilmente manipulado. Um ficheiro malicioso pode ser renomeado com uma extensão de aparência segura, e alguns sistemas ignoram completamente as extensões, tornando esta abordagem pouco fiável.
- Bytes mágicos: Estas são sequências fixas que se encontram no início de muitos ficheiros estruturados, como PDFs ou imagens. Este método melhora a precisão em relação às extensões de ficheiro, examinando o conteúdo real do ficheiro. A desvantagem é que nem todos os tipos de ficheiros têm padrões de bytes bem definidos. Os bytes mágicos também podem ser falsificados e a inconsistência de padrões entre ferramentas pode gerar confusão.
- Análise da distribuição de caracteres: Este método analisa o conteúdo real de um ficheiro para inferir o seu tipo. É particularmente útil para identificar formatos baseados em texto pouco estruturados, como scripts ou ficheiros de configuração. Embora forneça uma visão mais profunda, tem custos de processamento mais elevados e pode produzir falsos positivos com conteúdo invulgar. Também é menos eficaz para ficheiros binários que não possuem padrões de caracteres legíveis.
Estes métodos funcionam bem para formatos estruturados mas tornam-se pouco fiáveis quando aplicados a ficheiros não estruturados ou baseados em texto. Por exemplo, um script de shell com comandos mínimos pode assemelhar-se muito a um ficheiro de texto simples. Muitos destes ficheiros não têm cabeçalhos fortes ou marcadores consistentes, tornando insuficiente a classificação baseada em padrões de bytes ou extensões. Os atacantes exploram esta ambiguidade para disfarçar scripts maliciosos como documentos ou registos inofensivos.
As ferramentas antigas, como o TrID e o LibMagic, não foram concebidas para este nível de nuance. Embora eficazes para a categorização geral de ficheiros, foram optimizadas para a amplitude e velocidade, não para a deteção especializada sob restrições de segurança.
Como funciona o Modelo de Deteção de Tipo de Ficheiro v3
O processo de formação do Modelo de Deteção de Tipo de Ficheiro v3 consiste em duas fases. Na primeira fase, é efectuada uma pré-treino adaptada ao domínio utilizando a Modelação de Linguagem Mascarada (MLM), permitindo que o modelo aprenda a sintaxe e os padrões estruturais específicos do domínio. Na segunda fase, o modelo é aperfeiçoado num conjunto de dados supervisionado em que cada ficheiro é explicitamente anotado com o seu verdadeiro tipo de ficheiro.
O conjunto de dados é uma mistura selecionada de ficheiros regulares e amostras de ameaças, garantindo um forte equilíbrio entre a precisão do mundo real e a relevância da segurança. OPSWAT mantém o controlo sobre os dados de treino, permitindo um refinamento contínuo dos formatos mais importantes para as operações de segurança.
A componente de IA é aplicada com precisão e não de forma generalizada. O Modelo de Deteção de Tipo de Ficheiro v3 centra-se em tipos de ficheiros ambíguos e não estruturados que os métodos de deteção tradicionais não conseguem tratar eficazmente, tais como scripts, registos e texto pouco formatado em que a estrutura é inconsistente ou inexistente. O tempo médio de inferência permanece abaixo de 50 milissegundos, o que o torna eficiente para fluxos de trabalho em tempo real em uploads seguros de arquivos, aplicação de endpoints e pipelines de automação.
Resultados de referência
Comparámos o Motor de Deteção de Tipos de Ficheiros OPSWAT com as principais ferramentas de deteção de tipos de ficheiros, utilizando um conjunto de dados grande e diversificado. A comparação incluiu pontuações F1 em 248.000 ficheiros e aproximadamente 100 tipos de ficheiros.
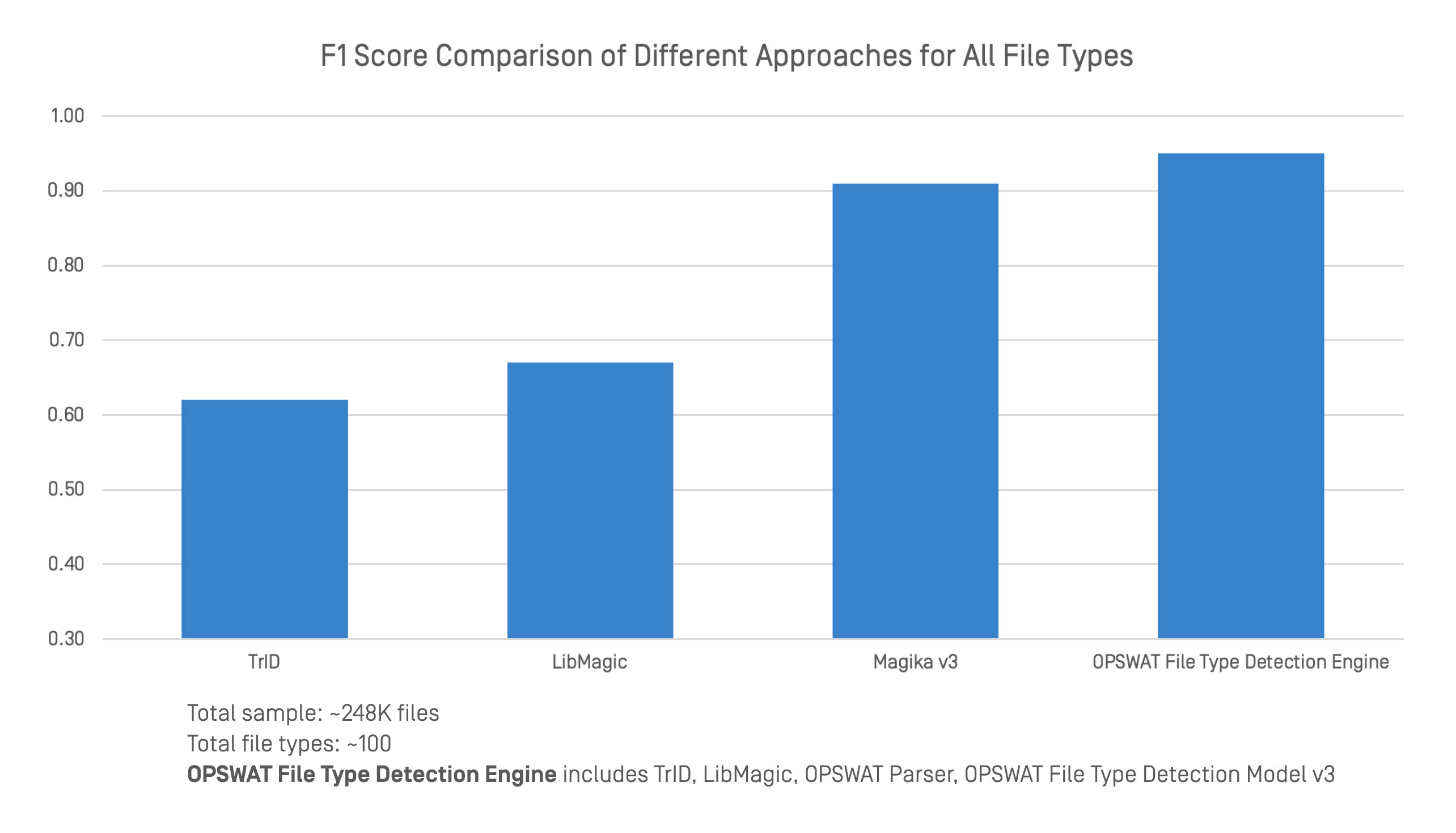
O Motor de Deteção de Tipos de Ficheiros OPSWAT integra várias técnicas, incluindo TrID, LibMagic e as próprias tecnologias do OPSWAT, tais como analisadores avançados e o Modelo de Deteção de Tipos de Ficheiros v3. Esta abordagem combinada proporciona uma classificação mais forte e mais fiável em formatos estruturados e não estruturados.
Nos testes de referência, o motor alcançou uma precisão geral mais elevada do que qualquer ferramenta isolada. Embora o TrID, o LibMagic e o Magika v3 tenham um bom desempenho em determinadas áreas, a sua precisão diminui quando faltam cabeçalhos de ficheiros ou o conteúdo é ambíguo. Ao combinar a deteção tradicional com a análise profunda do conteúdo, OPSWAT mantém um desempenho consistente mesmo quando a estrutura é fraca ou intencionalmente enganadora.
Ficheiros de texto e de script
Os formatos baseados em texto e script estão frequentemente envolvidos em ameaças transmitidas por ficheiros e movimentos laterais. Realizámos um teste específico em 169.000 ficheiros em formatos como .sh, .py, .ps1, e .conf.
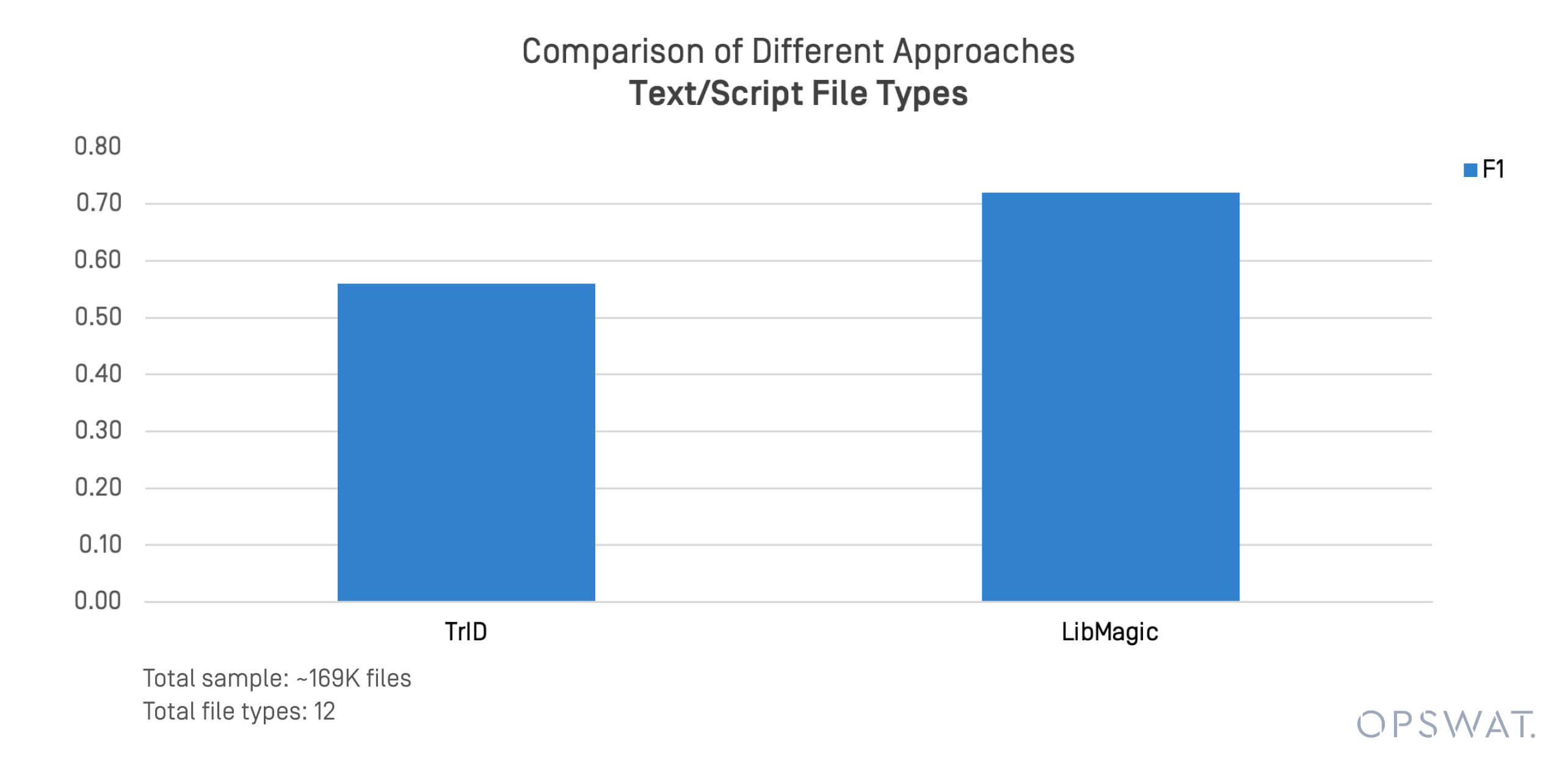
O TrID e o LibMagic mostraram limitações na deteção destes ficheiros não estruturados. O seu desempenho degradou-se rapidamente quando o conteúdo do ficheiro se desviou dos padrões de bytes esperados.
Modelo de deteção de tipo de ficheiro v3 vs Magika v3
Avaliámos o Modelo de Deteção de Tipos de Ficheiros v3 do OPSWAT contra o Magika v3, o classificador de IA de código aberto da Google, em 30 tipos de ficheiros de texto e de script, utilizando o mesmo conjunto de dados de 500 000 ficheiros.
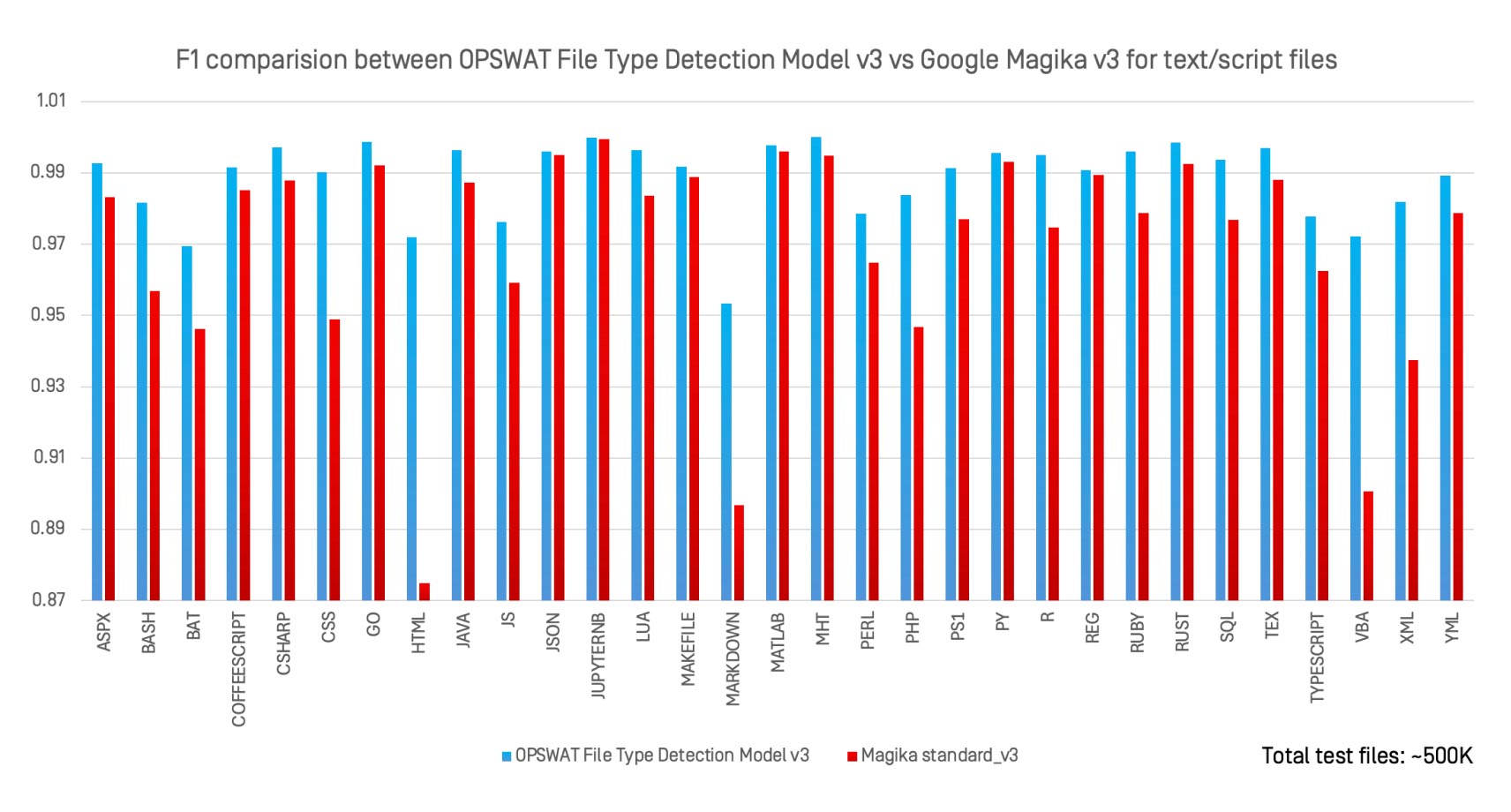
Principais observações:
- O Modelo de Deteção de Tipo de Ficheiro v3 igualou ou superou o Magika em quase todos os formatos.
- Os ganhos mais fortes foram registados em formatos vagamente definidos, tais como
.bat, .perl, .html,e .xml. - Ao contrário do Magika, que foi concebido para identificação de uso geral, o File Type Detection Model v3 é optimizado para formatos de alto risco em que a classificação incorrecta tem sérias implicações de segurança.
Principais casos de utilização
Carregamentos, transferências e transferências Secure de ficheiros
Evite que ficheiros disfarçados ou maliciosos entrem no seu ambiente através de portais Web, anexos de correio eletrónico ou sistemas de transferência de ficheiros. A deteção melhorada por IA vai além das extensões e dos cabeçalhos MIME para identificar scripts, macros ou executáveis incorporados em ficheiros renomeados.
Pipelines DevSecOps
Impeça artefatos inseguros antes que eles contaminem seus ambientes de criação ou implantação de software. Ao validar o verdadeiro tipo de arquivo com base no conteúdo real, MetaDefender Core garante que apenas formatos aprovados passem pelos pipelines de CI/CD, reduzindo o risco de ataques à cadeia de suprimentos e mantendo a conformidade com práticas de desenvolvimento seguras.
Aplicação da conformidade
A deteção precisa do tipo de ficheiro é essencial para cumprir mandatos regulamentares como HIPAA, PCI DSS, GDPR e NIST 800-53, que exigem um controlo rigoroso da integridade dos dados e da segurança do sistema. A deteção e o bloqueio de tipos de arquivo falsificados ou não autorizados ajudam a aplicar políticas que impedem a exposição de dados confidenciais, mantêm a prontidão da auditoria e evitam penalidades caras.
Considerações finais
Os classificadores de ficheiros de uso geral, como o Magika, são úteis para a categorização de conteúdos abrangentes. Mas na segurança cibernética, a precisão é mais importante do que a cobertura. Um único script mal classificado ou uma macro mal rotulada pode ser a diferença entre contenção e comprometimento.
O motor de deteção de tipos de ficheiros OPSWAT proporciona essa precisão. Ao combinar a análise de tipo de ficheiro melhorada por IA com métodos de deteção comprovados, fornece uma camada fiável de classificação onde as ferramentas tradicionais falham, especialmente em formatos ambíguos ou não estruturados. Não se trata de substituir tudo; trata-se de reforçar os pontos fracos críticos da sua pilha de segurança com deteção em tempo real e consciente do contexto.

